Cloudflare R2 SQLの実力は?ペタバイト級データに数秒で挑む、次世代データレイクの検証

はじめに
Cloudflareから新しい機能としてCloudflare R2 SQLがベータリリースされました。
Cloudflare Blog: https://blog.cloudflare.com/r2-sql-deep-dive/
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/get-started/
R2に保存したデータに対してSQLを実行できる機能です。 R2 Data Catalog(Apache Iceberg)を採用しており、ペタバイト級のデータ量でも数秒で結果を返せる性能を持つとのことです。
従来、R2に保存したデータはDuckDBなどのクエリエンジンで接続してからSQLを実行して分析することができましたが、R2 SQLを使用することでデータに対して直接SQLが実行できる ようになります。
この新しい機能を早速検証してみました。

Cloudflare Blog: https://blog.cloudflare.com/r2-sql-deep-dive/
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/get-started/
R2に保存したデータに対してSQLを実行できる機能です。 R2 Data Catalog(Apache Iceberg)を採用しており、ペタバイト級のデータ量でも数秒で結果を返せる性能を持つとのことです。
従来、R2に保存したデータはDuckDBなどのクエリエンジンで接続してからSQLを実行して分析することができましたが、R2 SQLを使用することでデータに対して直接SQLが実行できる ようになります。
この新しい機能を早速検証してみました。
動作検証
R2 SQLのアーキテクチャについては、先述のCloudflare Blogにて詳細が記載してありますので、そちらをご確認下さい。
本検証では、Cloudflare Pipelinesを使用してデータをR2に保存し、R2 SQLで確認します。
1.JSONデータをStreamのHTTPエンドポイントにPOSTします。
2.Pipelines -> syncを通して、parquet形式にデータを変換した後にR2バケットに保存されます。
3.バケットに保存されたテーブルデータに対し、promptからR2 SQLでクエリを実行してデータを取得します。
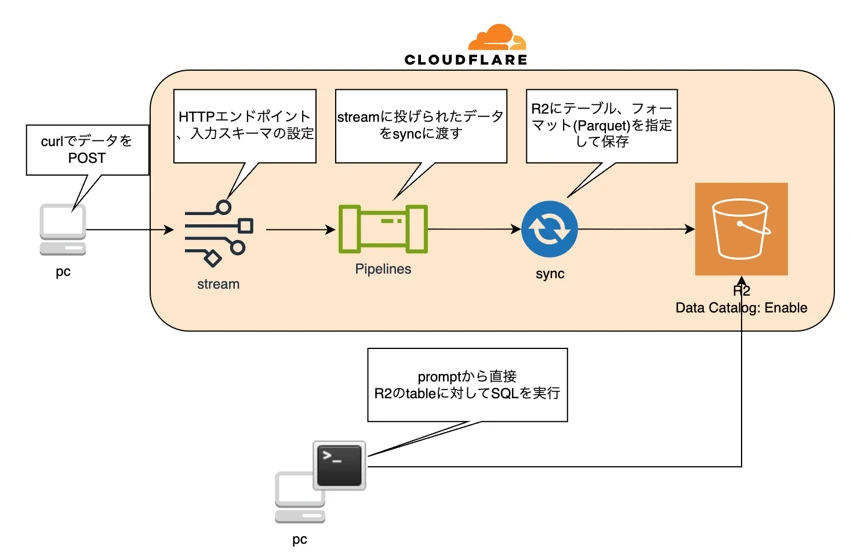
今回JSONデータを取り込んで変換するためにCloudflare Pipelinesを使用します。
それぞれの要素について簡単に説明します。
Cloudflare Doc: https://developers.cloudflare.com/pipelines/streams/
Cloudflare Pipelinesで処理するためにイベントを受信するキューです。
HTTPエンドポイントやCloudflare Workers Bindingを介してデータを取り込みます。
また、下流処理の遅延や障害発生時でもデータ損失を防ぐことができます。
Streamは現在、JSON形式のイベントを受け入れており、定義済みのスキーマを持つ構造化イベントと非構造化JSONの両方をサポートしています。
スキーマが指定されると、受信イベントに対して検証と適用が行われます。
Cloudflare Doc: https://developers.cloudflare.com/pipelines/pipelines/
Pipelinesは、SQL変換を介してStreamとSinkを接続し、イベントをストレージに書き込む前に変更することができます。
データがStreamからSinkに流れるときに、イベントをリアルタイムでフィルタリング、変換、再構築などが可能です。
Cloudflare Doc: https://developers.cloudflare.com/pipelines/sinks/
Cloudflare Pipelinesにおけるデータの送信先を定義します。
R2 Data CatalogへのApache Icebergテーブルとしての書き込み、またはR2への生のJSONファイルやParquetファイルとしての書き込みをサポートします。
Sinkは、イベントが重複したり欠落したりすることのないよう、1回限りの配信を保証します。
低レイテンシの取り込みのために頻繁にファイルを書き込むように設定することも、クエリパフォーマンスを向上させるために、より大容量のファイルを低頻度で書き込むように設定することもできます。
まずはR2バケットを作成して、Data Catalogを有効にします。
wranglerコマンドでCloudflareにログインし、アカウントを確認します。
R2バケットを以下コマンドで作成し、Data Catalogを有効化します。
Cloudflareの画面からバケットが作成されたことを確認します。
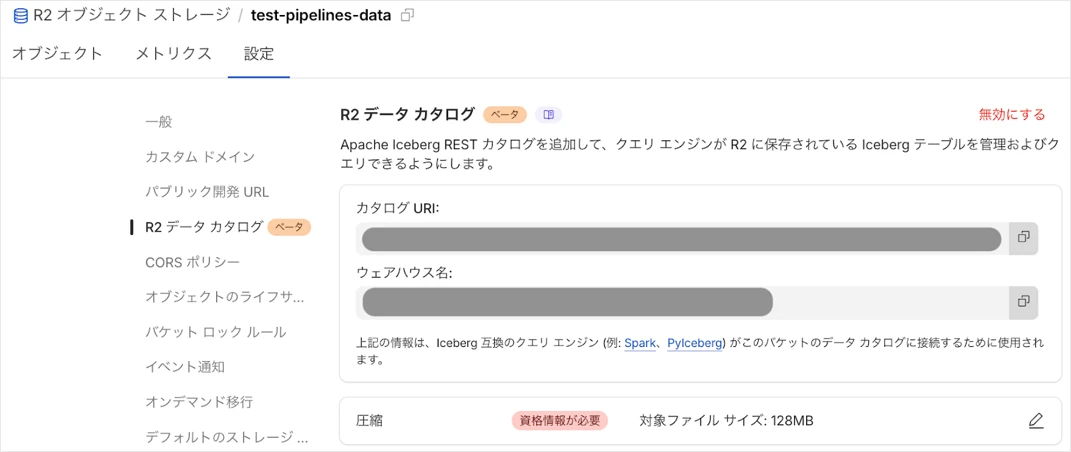
また、R2の設定からR2 データカタログが有効化されていることを確認します。
wranglerコマンドからデータカタログの情報の確認をすることも可能です。
R2 API Tokenを作成していきます。
R2の画面の以下の赤枠から進みます。
赤枠の「User APIトークンを作成する」をクリックします。
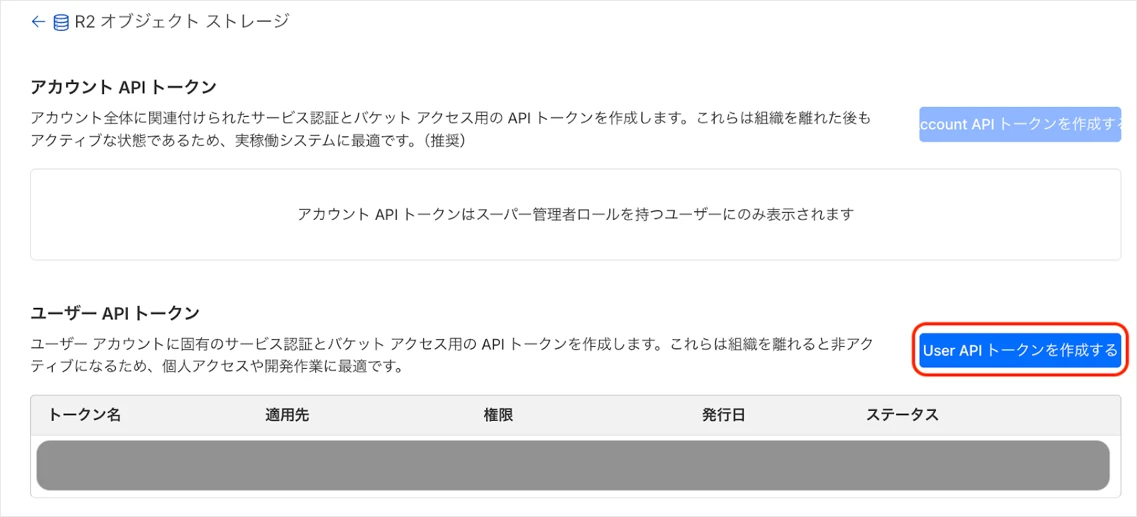
トークン名は任意の値を入力し、アクセス許可の権限タイプは「管理者読み取りと書き込み」を選択して作成します。
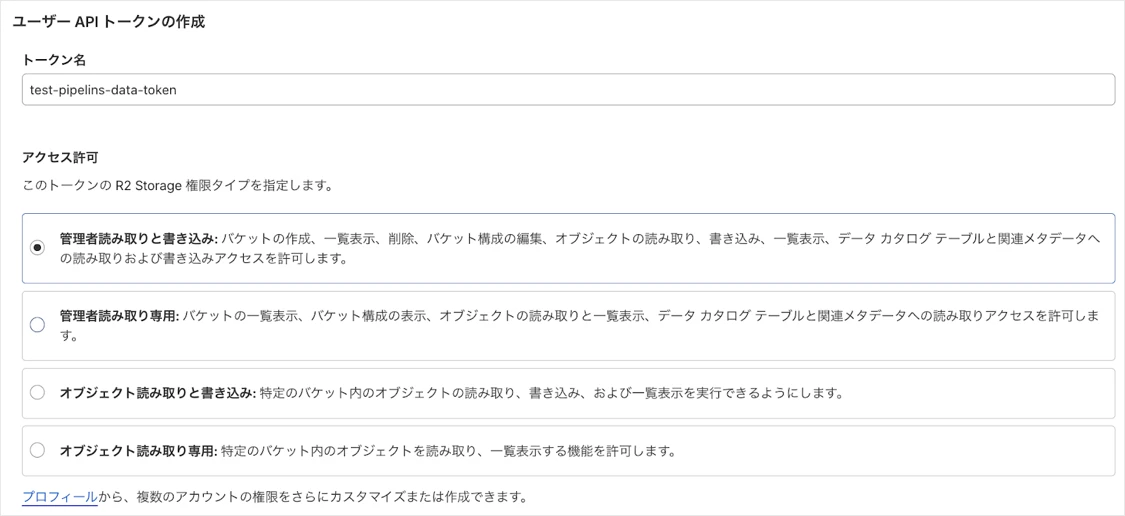
その後に表示されるトークンの値の値は後で使用するため、メモしておいて下さい。
以下のようなschema構成を作成していきます。

schema.jsonというファイルを作成して以下の内容を設定します。
以下のコマンドでPipelinesのセットアップを開始し、質問に答えていきます。
※太字の部分がユーザ入力した箇所になります。
※メモしたR2 API Tokenの値を使用します。
上記が完了するとCloudflareの画面から
・Pipelines
・Streams
・Sink
が作成されたことを確認できます。
Pipelinesの作成は、CloudflareのPipelinesの画面からも可能です。

コマンドでエラーが出た場合は画面から試すとトラブルシューティングしやすいかもしれません。
作成したPipelinesが表示されています。
クリックしてみると、Pipelines + Stream +Sinkの接続情報が確認できます。
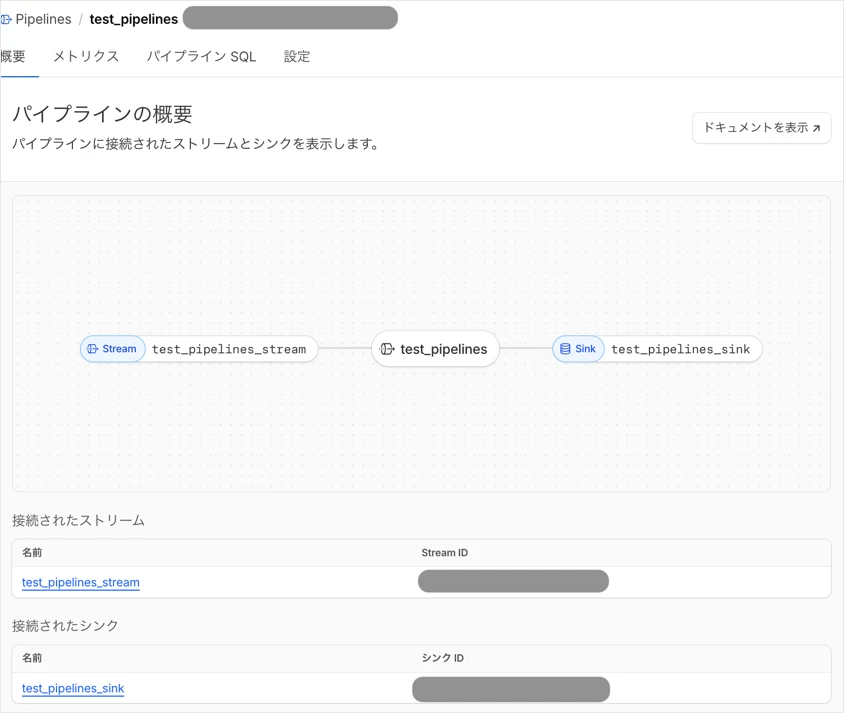
また、メトリクスからPipelinesのデータの使用状況の確認ができます。
作成したStreamが表示されています。
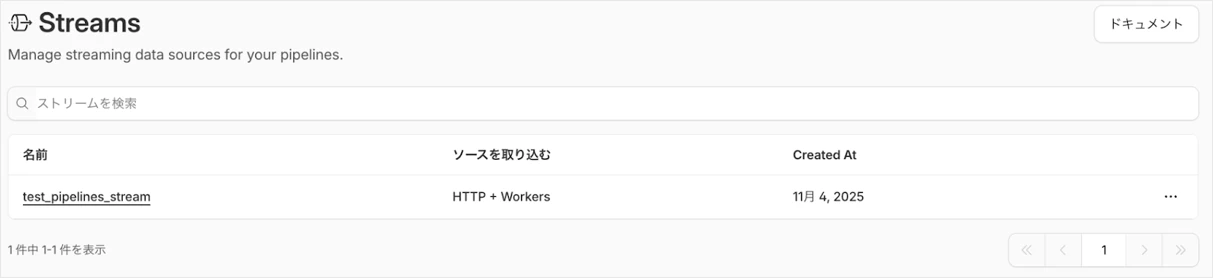
クリックしてみると、HTTPのエンドポイント、テーブルのschema情報などが確認できます。
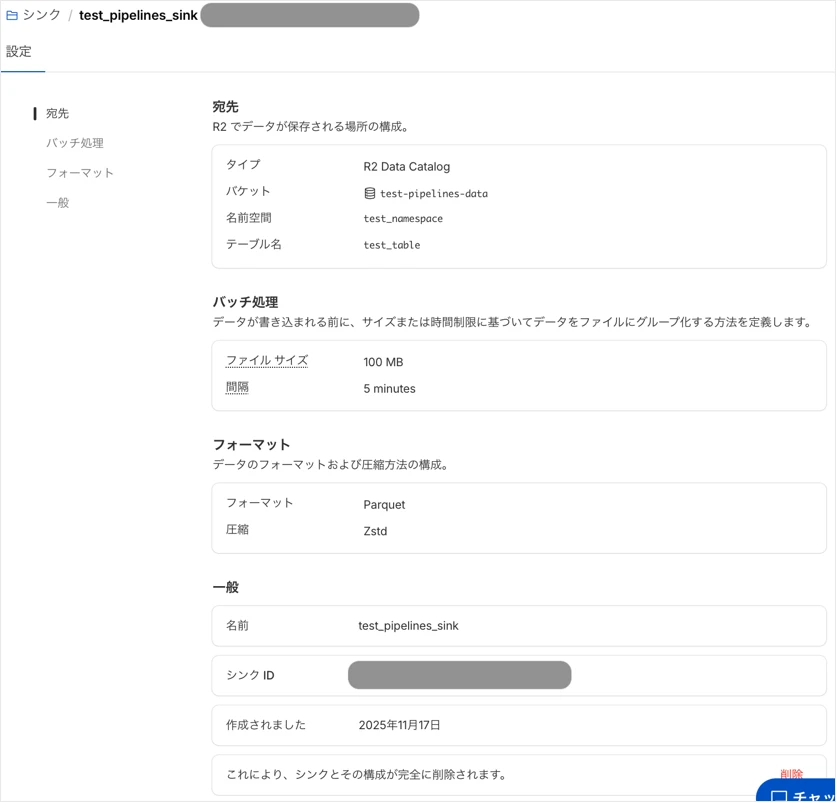
作成したSinkが表示されています。
クリックしてみると、データの名前空間、テーブル名などの確認が可能です。
以下のcurlコマンドを使用して、データが取り込まれるか確認します。
dateは登録したい日時をUNIX時刻(ミリ秒)に変換しておきます。
※{ stream-id }はCloudflareのstreamの画面から確認が可能です。
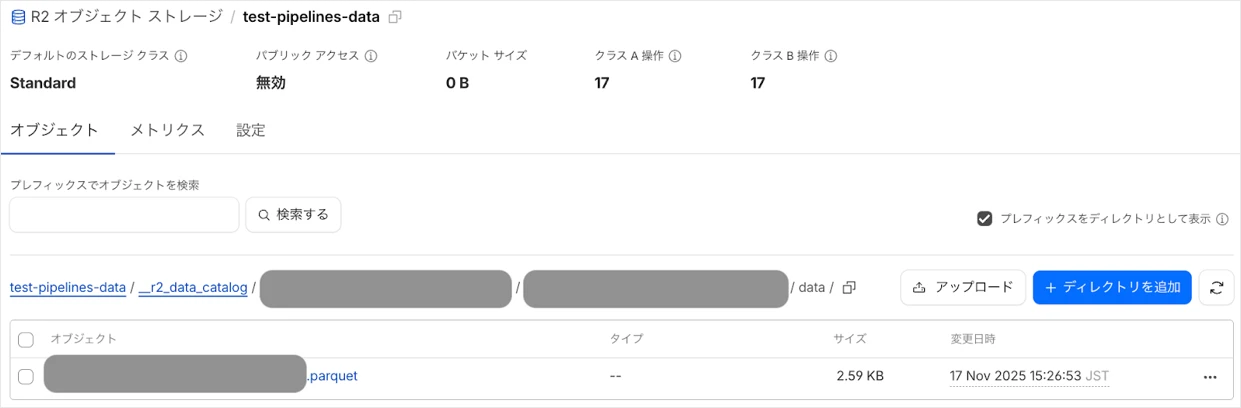
R2バケット内にparquetファイルが作成されていることを確認できました。
※ファイルが作成されるまで少し時間がかかる場合があります。
.envファイルを作成します。
```
WRANGLER_R2_SQL_AUTH_TOKEN=R2 API TOKENの値
```
.envファイルと同じ場所で以下コマンドを実行します。
※Data Catalogのウェアハウス名は、Cloudflareの画面のR2バケット -> 該当のバケット -> 設定 -> R2 データ カタログから確認が可能です。
実行結果として、先程POSTした内容が表示されたことを確認できます。
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/query-data/#query-via-api
CloudflareのAPI経由からもR2 SQLを実行することが可能です。
成功すると以下の結果が得られます。
現状R2 SQLで使用できるクエリは以下にまとめてあります。
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/sql-reference/
SELECT系のコマンドは使用可能ですが、INSERTなどのデータ操作系コマンドは利用できません。使用前に一度確認しておくことをお勧めします。
Cloudflare Blogにて今後の展開が記載されています。
Cloudflare Blog: https://blog.cloudflare.com/r2-sql-deep-dive/#future-plans
簡潔にまとめると以下の機能のリリースが予定されているとのことです。
・複雑な集計方法のサポート
・クエリ実行の可視性
・Apache Iceberg がサポートする多くの構成オプションをサポート
・CloudflareダッシュボードからR2 SQLのクエリ実行
Cloudflareダッシュボードから実行できるようになれば、より多くの方が容易にアクセスできるようになり、データ解析の範囲が広がりそうです。
今回の検証の構成図
本検証では、Cloudflare Pipelinesを使用してデータをR2に保存し、R2 SQLで確認します。
1.JSONデータをStreamのHTTPエンドポイントにPOSTします。
2.Pipelines -> syncを通して、parquet形式にデータを変換した後にR2バケットに保存されます。
3.バケットに保存されたテーブルデータに対し、promptからR2 SQLでクエリを実行してデータを取得します。
Stream, Pipelines, syncの概要
今回JSONデータを取り込んで変換するためにCloudflare Pipelinesを使用します。
それぞれの要素について簡単に説明します。
Stream概要
Cloudflare Doc: https://developers.cloudflare.com/pipelines/streams/
Cloudflare Pipelinesで処理するためにイベントを受信するキューです。
HTTPエンドポイントやCloudflare Workers Bindingを介してデータを取り込みます。
また、下流処理の遅延や障害発生時でもデータ損失を防ぐことができます。
Streamは現在、JSON形式のイベントを受け入れており、定義済みのスキーマを持つ構造化イベントと非構造化JSONの両方をサポートしています。
スキーマが指定されると、受信イベントに対して検証と適用が行われます。
Pipelines概要
Cloudflare Doc: https://developers.cloudflare.com/pipelines/pipelines/
Pipelinesは、SQL変換を介してStreamとSinkを接続し、イベントをストレージに書き込む前に変更することができます。
データがStreamからSinkに流れるときに、イベントをリアルタイムでフィルタリング、変換、再構築などが可能です。
Sink概要
Cloudflare Doc: https://developers.cloudflare.com/pipelines/sinks/
Cloudflare Pipelinesにおけるデータの送信先を定義します。
R2 Data CatalogへのApache Icebergテーブルとしての書き込み、またはR2への生のJSONファイルやParquetファイルとしての書き込みをサポートします。
Sinkは、イベントが重複したり欠落したりすることのないよう、1回限りの配信を保証します。
低レイテンシの取り込みのために頻繁にファイルを書き込むように設定することも、クエリパフォーマンスを向上させるために、より大容量のファイルを低頻度で書き込むように設定することもできます。
R2バケットの作成
まずはR2バケットを作成して、Data Catalogを有効にします。
Cloudflareにログイン
wranglerコマンドでCloudflareにログインし、アカウントを確認します。
$ npx wrangler login
$ npx wrangler whoami
R2バケットの作成と設定
R2バケットを以下コマンドで作成し、Data Catalogを有効化します。
$ npx wrangler r2 bucket create test-pipelines-data
$ npx wrangler r2 bucket catalog enable test-pipelines-data
Cloudflareの画面からバケットが作成されたことを確認します。
また、R2の設定からR2 データカタログが有効化されていることを確認します。
wranglerコマンドからデータカタログの情報の確認をすることも可能です。
$ npx wrangler r2 bucket catalog get test-pipelines-data
Getting data catalog status for 'test-pipelines-data'...
Catalog URI: https://catalog.cloudflarestorage.com/xxxxx/test-pipelines-data
Warehouse: xxxxx_test-pipelines-data
Status: active
R2のAPI Tokenの作成
R2 API Tokenを作成していきます。
R2の画面の以下の赤枠から進みます。
赤枠の「User APIトークンを作成する」をクリックします。
トークン名は任意の値を入力し、アクセス許可の権限タイプは「管理者読み取りと書き込み」を選択して作成します。
その後に表示されるトークンの値の値は後で使用するため、メモしておいて下さい。
Pipelinesの作成
schemaの作成
以下のようなschema構成を作成していきます。
schema.jsonというファイルを作成して以下の内容を設定します。
{ "fields": [
{
"name": "user_id",
"type": "int32",
"required": true
},
{
"name": "name",
"type": "string",
"required": true
},
{
"name": "remarks",
"type": "string",
"required": false
},
{
"name": "membership",
"type": "bool",
"required": true
},
{
"name": "date",
"type": "timestamp",
"required": true
}
]
}Pipelinesのセットアップと作成
以下のコマンドでPipelinesのセットアップを開始し、質問に答えていきます。
$ npx wrangler pipelines setup
※太字の部分がユーザ入力した箇所になります。
※メモしたR2 API Tokenの値を使用します。
[WARNING] `wrangler pipelines setup` is an open-beta command. Please report any issues to https://github.com/cloudflare/workers-sdk/issues/new/choose
Welcome to Cloudflare Pipelines Setup!
This will guide you through creating a complete pipeline: stream → pipeline → sink
What would you like to name your pipeline? … test_pipelines
Let's configure your data source (stream):
Enable HTTP endpoint for sending data? … yes
Require authentication for HTTP endpoint? … no
Configure custom CORS origins? … no
How would you like to define the schema? › Load from file
Schema file path: … schema.json
Stream configuration complete
Let's configure your destination (sink):
Select destination type: › Data Catalog Table
R2 bucket name (for catalog storage): … test-pipelines-data
Namespace: … test_namespace
Table name: … test_table
Catalog API token: … ****************************************(R2 API Tokenの値を入力)
Compression: › zstd
Roll file when size reaches (MB, minimum 5): … 100
Roll file when time reaches (seconds, minimum 10): … 300
Sink configuration complete
Configuration Summary:
Stream: test_pipelines_stream
• HTTP: Enabled
• Authentication: None
• Schema: 4 fields
Sink: test_pipelines_sink
• Type: Data Catalog
• Table: default/test-table
Create stream and sink? … yes
Creating stream...
Created stream: test_pipelines_stream
Creating sink...
Created sink: test_pipelines_sink
Stream and sink created successfully!
Pipeline SQL:
Available tables:
• test_pipelines_stream (source stream)
• test_pipelines_sink (destination sink)
Stream input schema:
┌────────────┬───────────┬────────────┬──────────┐
│ Field Name │ Type │ Unit/Items │ Required │
├────────────┼───────────┼────────────┼──────────┤
│ user_id │ int32 │ │ Yes │
├────────────┼───────────┼────────────┼──────────┤
│ name │ string │ │ Yes │
├────────────┼───────────┼────────────┼──────────┤
│ remarks │ string │ │ No │
├────────────┼───────────┼────────────┼──────────┤
│ membership │ bool │ │ Yes │
├────────────┼───────────┼────────────┼──────────┤
│ date │ timestamp │ │ Yes │
└────────────┴───────────┴────────────┴──────────┘
How would you like to provide SQL that will define how your pipeline will transform and route data? › Use simple ingestion query (copy all data from stream to sink)
Using query: INSERT INTO test_pipelines_sink SELECT * FROM test_pipelines_stream;
Validating SQL...
SQL validation passed. References tables: test_pipelines_sink, test_pipelines_stream
SQL configuration complete
Creating pipeline...
Created pipeline: test_pipelines
Setup complete!
Send your first event to stream 'test_pipelines_stream':
Worker Integration:
To access your new Pipeline in your Worker, add the following snippet to your configuration file:
{
"pipelines": [
{
"pipeline": "xxxxxxxxx",
"binding": "TEST_PIPELINES_STREAM"
}
]
}
In your Worker:
await env.TEST_PIPELINES_STREAM.send([{
"user_id": 42,
"name": "sample_name",
"remarks": "sample_remarks",
"membership": true,
"date": 1763358799436
}]);
HTTP Endpoint:
curl -X POST https://b8b645b3f3dc4717b0d364639c94cf09.ingest.cloudflare.com
-H "Content-Type: application/json"
-d '[{
"user_id": 42,
"name": "sample_name",
"remarks": "sample_remarks",
"membership": true,
"date": 1763358799436
}]'
上記が完了するとCloudflareの画面から
・Pipelines
・Streams
・Sink
が作成されたことを確認できます。
Pipelinesの作成は、CloudflareのPipelinesの画面からも可能です。
コマンドでエラーが出た場合は画面から試すとトラブルシューティングしやすいかもしれません。
Pipelines画面
作成したPipelinesが表示されています。
クリックしてみると、Pipelines + Stream +Sinkの接続情報が確認できます。
また、メトリクスからPipelinesのデータの使用状況の確認ができます。
Stream画面
作成したStreamが表示されています。
クリックしてみると、HTTPのエンドポイント、テーブルのschema情報などが確認できます。
Sinks画面
作成したSinkが表示されています。
クリックしてみると、データの名前空間、テーブル名などの確認が可能です。
データのPOST
以下のcurlコマンドを使用して、データが取り込まれるか確認します。
dateは登録したい日時をUNIX時刻(ミリ秒)に変換しておきます。
※{ stream-id }はCloudflareのstreamの画面から確認が可能です。
$ curl -X POST https://{ stream-id }.ingest.cloudflare.com
-H "Content-Type: application/json"
-d '[{
"user_id": 42,
"name": "yotaro",
"remarks": "テスト備考001",
"membership": true,
"date": 1763358799436
}]'R2バケット内にparquetファイルが作成されていることを確認できました。
※ファイルが作成されるまで少し時間がかかる場合があります。
R2 SQLの実行
wranglerコマンドから実行
.envファイルを作成します。
```
WRANGLER_R2_SQL_AUTH_TOKEN=R2 API TOKENの値
```
.envファイルと同じ場所で以下コマンドを実行します。
※Data Catalogのウェアハウス名は、Cloudflareの画面のR2バケット -> 該当のバケット -> 設定 -> R2 データ カタログから確認が可能です。
$ npx wrangler r2 sql query "{ data catalogのウェアハウス名 }" "
SELECT
user_id,
name,
remarks,
membership,
date
FROM test_namespace.test_table
"
┌─────────┬────────┬───────────────┬────────────┬─────────────────────────────┐
│ user_id │ name │ remarks │ membership │ date │
├─────────┼────────┼───────────────┼────────────┼─────────────────────────────┤
│ 42 │ yotaro │ テスト備考001 │ true │ 2025-11-17T05:53:19.436000Z │
└─────────┴────────┴───────────────┴────────────┴─────────────────────────────┘
Read 1.49 kB across 1 files from R2
On average, 356 B / s実行結果として、先程POSTした内容が表示されたことを確認できます。
APIからR2 SQL実行
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/query-data/#query-via-api
CloudflareのAPI経由からもR2 SQLを実行することが可能です。
$ curl -X POST
"https://api.sql.cloudflarestorage.com/api/v1/accounts/{ACCOUNT_ID}/r2-sql/query/{BUCKET_NAME}"
-H "Authorization: Bearer ${R2_API_TOKEN}"
-H "Content-Type: application/json"
-d '{
"query": "SELECT * FROM test_namespace.test_table;"
}' | jq .
成功すると以下の結果が得られます。
{ "result": {
"request_id": "dqe-prod-xxxxx",
"schema": [
{
"name": "__ingest_ts",
"descriptor": {
"type": {
"name": "timestamp",
"time_unit": "microsecond",
"time_zone": null
},
"nullable": false
}
},
{
"name": "user_id",
"descriptor": {
"type": {
"name": "int32"
},
"nullable": false
}
},
{
"name": "name",
"descriptor": {
"type": {
"name": "string"
},
"nullable": false
}
},
{
"name": "remarks",
"descriptor": {
"type": {
"name": "string"
},
"nullable": true
}
},
{
"name": "membership",
"descriptor": {
"type": {
"name": "bool"
},
"nullable": false
}
},
{
"name": "date",
"descriptor": {
"type": {
"name": "timestamp",
"time_unit": "microsecond",
"time_zone": null
},
"nullable": false
}
}
],
"rows": [
{
"__ingest_ts": "2025-11-17T06:21:45.000000Z",
"user_id": 42,
"name": "yotaro",
"remarks": "テスト備考001",
"membership": true,
"date": "2025-11-17T05:53:19.436000Z"
}
],
"metrics": {
"r2_requests_count": 8,
"files_scanned": 1,
"bytes_scanned": 1492
}
},
"success": true,
"errors": [],
"messages": []}R2 SQLで使用できるクエリ
現状R2 SQLで使用できるクエリは以下にまとめてあります。
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/sql-reference/
SELECT系のコマンドは使用可能ですが、INSERTなどのデータ操作系コマンドは利用できません。使用前に一度確認しておくことをお勧めします。
今後のロードマップ
Cloudflare Blogにて今後の展開が記載されています。
Cloudflare Blog: https://blog.cloudflare.com/r2-sql-deep-dive/#future-plans
簡潔にまとめると以下の機能のリリースが予定されているとのことです。
・複雑な集計方法のサポート
・クエリ実行の可視性
・Apache Iceberg がサポートする多くの構成オプションをサポート
・CloudflareダッシュボードからR2 SQLのクエリ実行
Cloudflareダッシュボードから実行できるようになれば、より多くの方が容易にアクセスできるようになり、データ解析の範囲が広がりそうです。
最後に
簡単ですがCloudflare R2 SQLを検証しました。
まだベータ版のため利用できる機能は限定的ですが、 今後新しい機能が拡大されていけば、データ解析を行うための機能がCloudflareだけで完結できるようになることが期待されます。
これにより、データ解析のためにデータを様々な場所に転送したり変換したりする作業が減り、シンプルな構成にすることができるため運用負荷が下がりそうです。
料金に関してはまだ正式に発表されてませんが、現段階ではベータ版のため料金はかからないとのことです。
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/platform/pricing/
データ解析を行う上で非常に便利な構成が構築できるため、今後が楽しみな機能です。
そしてCloudflareなら上記以外でも、
・パフォーマンスの向上
・サイトの信頼性の向上
・セキュリティの向上
が、一つのサービスで実現できますので非常におすすめです。
まだベータ版のため利用できる機能は限定的ですが、 今後新しい機能が拡大されていけば、データ解析を行うための機能がCloudflareだけで完結できるようになることが期待されます。
これにより、データ解析のためにデータを様々な場所に転送したり変換したりする作業が減り、シンプルな構成にすることができるため運用負荷が下がりそうです。
料金に関してはまだ正式に発表されてませんが、現段階ではベータ版のため料金はかからないとのことです。
Cloudflare Doc: https://developers.cloudflare.com/r2-sql/platform/pricing/
データ解析を行う上で非常に便利な構成が構築できるため、今後が楽しみな機能です。
そしてCloudflareなら上記以外でも、
・パフォーマンスの向上
・サイトの信頼性の向上
・セキュリティの向上
が、一つのサービスで実現できますので非常におすすめです。
Cloudflareに、アクセリアの運用サポートをプラスしたCDNサービスを提供しています
アクセリア自社CDNの開発と運用は、20年以上にわたります。それらの経験とノウハウを駆使したプロフェッショナルサポートをパッケージしたサービスが、[Solution CDN]です。
移行支援によるスムーズな導入とともに、お客様の運用負担を最小限にとどめながら、WEBサイトのパフォーマンスとセキュリティを最大限に高めます。運用サポートはフルアウトソーシングからミニマムサポートまで、ご要望に合わせてご提供します。
Cloudflare(クラウドフレア)の導入や運用について、またそれ以外のことでもなにか気になることがございましたらお気軽にご相談下さい。
移行支援によるスムーズな導入とともに、お客様の運用負担を最小限にとどめながら、WEBサイトのパフォーマンスとセキュリティを最大限に高めます。運用サポートはフルアウトソーシングからミニマムサポートまで、ご要望に合わせてご提供します。
Cloudflare(クラウドフレア)の導入や運用について、またそれ以外のことでもなにか気になることがございましたらお気軽にご相談下さい。
杉木 俊文
アクセリア株式会社 サービス事業本部プラットフォーム部










Contact usお問い合わせ
サービスにご興味をお持ちの方は
お気軽にお問い合わせください。
Webからお問い合わせ
お問い合わせお電話からお問い合わせ
03-5211-7750
平日09:30 〜 18:00
Free Service