Analyzing Debian packages with Neo4j - Part 3 Getting data from UDD into Neo4j

Pulling data from the Ultimate Debian Database UDD
In the first part and the second part of this series of articles on analyzing Debian packages with Neo4j we gave a short introduction to Debian and the life time and structure of Debian packages, as well as developed the database scheme, that is the set of nodes and relations and their attributes used in the representation of Debian packages.(first part , second part)
The current third (and last) part deals with the technical process of actually pulling the information from the Ultimate Debian Database UDD and getting it into Neo4j. We will close with a few sample queries and discuss possible future work.
The process of pulling the data and entering into Neo4j consisted of three steps:
・Dumping the relevant information from the UDD,
・Parsing the output of the previous step and building up a list of nodes and relations,
・Creating a Neo4j database from the set of nodes and relations.
The UDD has a public mirror at https://udd-mirror.debian.net/ which is accessible via a PostgreSQL client.
For the current status we only dumped information from two tables, namely the tables sources and packages, from which we dumped the relevant information discussed in the previous blog post.
The complete SQL query for the sources table was SELECT source,version,maintainer_email,maintainer_name,release,uploaders,bin,architecture,build_depends,
build_depends_indep,build_conflicts,build_conflicts_indep from sources ; while the one for the packages table was SELECT package,version,maintainer_email,maintainer_name,release,description,depends,recommends,suggests,
conflicts,breaks,provides,replaces,pre_depends,enhances from packages ;.
We first tried to use the command line client psql but due to the limited output format options of the client we decided to switch to a Perl script that uses the database access modules, and then dumped the output immediately into a Perl readable format for the next step.
The complete script can be accessed at the Github page of the project: pull-udd.pl.
Generating the list of nodes and relations The complicated part of the process lies in the conversion from database tables to a graph with nodes and relations. We developed a Perl script that reads in the two tables dumped in the first step, and generates for each node and relation type a CSV file consisting of the a unique ID and the attributes listed at the end of the last blog post.
The Perl script generate-graph operates in two steps: first it reads in the dump files and creates a unique structure (hash of hashes) that collects all the information necessary. This first step is necessary due to the heavy duplication of information in the dumps (maintainers, packages, etc, all appear several times but need to be merged into a single entity).
We also generate for each node entity (each source package, binary package etc) unique id (UUID) so that we can later reference these nodes when building up the relations.
The final step consists of computing the relations from the data parsed, creating additional nodes on the way (in particular for alternative dependencies), and writing out all the CSV files.
Complications encountered
As expected, there were a lot of steps from the first version to the current working version, in particular due to the following reasons (to name a few):
・Maintainers are identified by email, but they sometimes use different names
・Ordering of version numbers is non-trivial due to binNMU uploads and other version string tricks
・Different version of packages in different architectures
・udeb (installer) packages
The current third (and last) part deals with the technical process of actually pulling the information from the Ultimate Debian Database UDD and getting it into Neo4j. We will close with a few sample queries and discuss possible future work.
The process of pulling the data and entering into Neo4j consisted of three steps:
・Dumping the relevant information from the UDD,
・Parsing the output of the previous step and building up a list of nodes and relations,
・Creating a Neo4j database from the set of nodes and relations.
The UDD has a public mirror at https://udd-mirror.debian.net/ which is accessible via a PostgreSQL client.
For the current status we only dumped information from two tables, namely the tables sources and packages, from which we dumped the relevant information discussed in the previous blog post.
The complete SQL query for the sources table was SELECT source,version,maintainer_email,maintainer_name,release,uploaders,bin,architecture,build_depends,
build_depends_indep,build_conflicts,build_conflicts_indep from sources ; while the one for the packages table was SELECT package,version,maintainer_email,maintainer_name,release,description,depends,recommends,suggests,
conflicts,breaks,provides,replaces,pre_depends,enhances from packages ;.
We first tried to use the command line client psql but due to the limited output format options of the client we decided to switch to a Perl script that uses the database access modules, and then dumped the output immediately into a Perl readable format for the next step.
The complete script can be accessed at the Github page of the project: pull-udd.pl.
The Perl script generate-graph operates in two steps: first it reads in the dump files and creates a unique structure (hash of hashes) that collects all the information necessary. This first step is necessary due to the heavy duplication of information in the dumps (maintainers, packages, etc, all appear several times but need to be merged into a single entity).
We also generate for each node entity (each source package, binary package etc) unique id (UUID) so that we can later reference these nodes when building up the relations.
The final step consists of computing the relations from the data parsed, creating additional nodes on the way (in particular for alternative dependencies), and writing out all the CSV files.
Complications encountered
As expected, there were a lot of steps from the first version to the current working version, in particular due to the following reasons (to name a few):
・Maintainers are identified by email, but they sometimes use different names
・Ordering of version numbers is non-trivial due to binNMU uploads and other version string tricks
・Different version of packages in different architectures
・udeb (installer) packages
Creating a Neo4j Database
The last step was creating a Neo4j database from the CSV files of nodes and relations. Our first approach was not via CSV files but using Cypher statements to generate nodes and relationships. This turned out to be completely infeasible, since each Cypher statement requires updates in the database. I estimated the time for complete data entry (automated) to several weeks.
Neo4j recommends using the neo4j-import tool, which create a new Neo4j database from data in CSV files. The required format is rather simple, one CSV file for each node and relation type containing a unique id plus other attributes in columns. The CSV files for relations then link the unique ids, and can also add further attributes.
To give an example, let us look at the head of the CSV for source packages sp, which has besides the name no further attribute:
uuid:ID,name
id0005a566e2cc46f295636dee7d504e82,libtext-ngrams-perl
id00067d4a790c429b9428b565b6bddae2,yocto-reader
id000876d57c85440e899cb93db27c835e,python-mhash
We see the unique id, which is tagged with :ID (see the neo4j-import tool manual for details), and the name of the source package.
The CSV files defining relations all look similar:
:START_ID,:END_ID
id000072be5fd749328d0ec4c0ecc875f9,ide234044ae378493ab0af0151f775b8fe
id000082711b4b4076922b5982d09b611b,ida404df8388a149479b130d6692c60f5e
id000082711b4b4076922b5982d09b611b,idb5c2195d5b8f42bfbb9baa5fad6a066e
That is a list of start and end ids. In case of additional attributes like in the case of the dependsrelation we have
:START_ID,reltype,relversion,:END_ID
id00001319368f4e32993d49a8b1e61673,none,1,idcd55489608944012a02eadde55cbfa9e
id0000143632404ad386e4564b3917a27c,>=,0.8-0,id156130a5c32a47d3918d3a4f4faff16f
id0000143632404ad386e4564b3917a27c,>=,2.14.2-3,id1acca938752543efa4de87c60ff7b279
After having prepared these CSV files, a simple call to neo4j-import generates the Neo4j database in a new directory. Since we changed the set of nodes and relations several times, we named the generated files node-XXX.csv and edge-XXX.csv and generated the neo4j-import call automatically, see build-db script. This call takes, in contrast to the execution of the Cypher statements, a few seconds (!) to create the whole database:
$ neo4j-import ...
...
IMPORT DONE in 10s 608ms.
Imported:
528073 nodes
4539206 relationships
7540954 properties
Peak memory usage: 521.28 MB
Looking at the script build-all that glues everything together we see another step (sort-uniq) which makes sure that the same UUID is not listed multiple times.
Neo4j recommends using the neo4j-import tool, which create a new Neo4j database from data in CSV files. The required format is rather simple, one CSV file for each node and relation type containing a unique id plus other attributes in columns. The CSV files for relations then link the unique ids, and can also add further attributes.
To give an example, let us look at the head of the CSV for source packages sp, which has besides the name no further attribute:
uuid:ID,name
id0005a566e2cc46f295636dee7d504e82,libtext-ngrams-perl
id00067d4a790c429b9428b565b6bddae2,yocto-reader
id000876d57c85440e899cb93db27c835e,python-mhash
We see the unique id, which is tagged with :ID (see the neo4j-import tool manual for details), and the name of the source package.
The CSV files defining relations all look similar:
:START_ID,:END_ID
id000072be5fd749328d0ec4c0ecc875f9,ide234044ae378493ab0af0151f775b8fe
id000082711b4b4076922b5982d09b611b,ida404df8388a149479b130d6692c60f5e
id000082711b4b4076922b5982d09b611b,idb5c2195d5b8f42bfbb9baa5fad6a066e
That is a list of start and end ids. In case of additional attributes like in the case of the dependsrelation we have
:START_ID,reltype,relversion,:END_ID
id00001319368f4e32993d49a8b1e61673,none,1,idcd55489608944012a02eadde55cbfa9e
id0000143632404ad386e4564b3917a27c,>=,0.8-0,id156130a5c32a47d3918d3a4f4faff16f
id0000143632404ad386e4564b3917a27c,>=,2.14.2-3,id1acca938752543efa4de87c60ff7b279
After having prepared these CSV files, a simple call to neo4j-import generates the Neo4j database in a new directory. Since we changed the set of nodes and relations several times, we named the generated files node-XXX.csv and edge-XXX.csv and generated the neo4j-import call automatically, see build-db script. This call takes, in contrast to the execution of the Cypher statements, a few seconds (!) to create the whole database:
$ neo4j-import ...
...
IMPORT DONE in 10s 608ms.
Imported:
528073 nodes
4539206 relationships
7540954 properties
Peak memory usage: 521.28 MB
Looking at the script build-all that glues everything together we see another step (sort-uniq) which makes sure that the same UUID is not listed multiple times.
Sample queries
Let us conclude with a few sample queries: First we want to find all packages in Jessie that build depends on tex-common. For this we use the Neo4j visualization kit and write Cypher statements to query and return the relevant nodes and relations:
match (BP:bp)<-[:build_depends]-(VSP:vsp)-[:builds]->(VBP:vbp)<-[:contains]-(S:suite)
where BP.name="tex-common" and S.name="jessie"
return BP, VSP, VBP, S
This query would give us more or less the following graph:
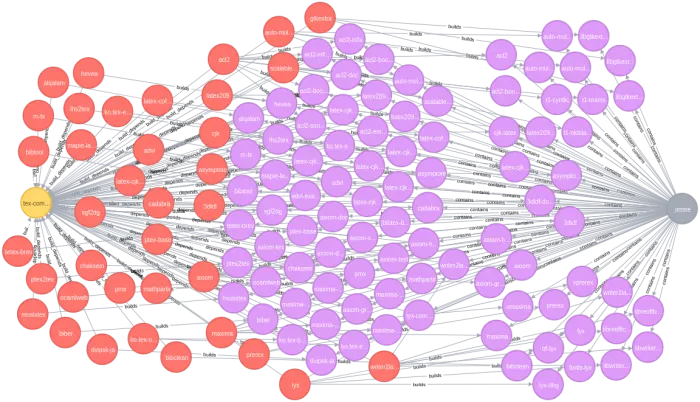
(click to enlarge)
match (S:suite)-[:contains]->(VBP:vbp)-[:builds]-(VSP:vsp)-[:build_depends]-(X:bp)
where S.name = "sid"
with X.name as pkg,count(VSP) as cntr
return pkg,cntr order by -cntr
which returns the top package debhelper with 55438 packages build-depending on it, followed by dh-python (9289) and pkg-config (9102).
match (BP:bp)<-[:build_depends]-(VSP:vsp)-[:builds]->(VBP:vbp)<-[:contains]-(S:suite)
where BP.name="tex-common" and S.name="jessie"
return BP, VSP, VBP, S
This query would give us more or less the following graph:
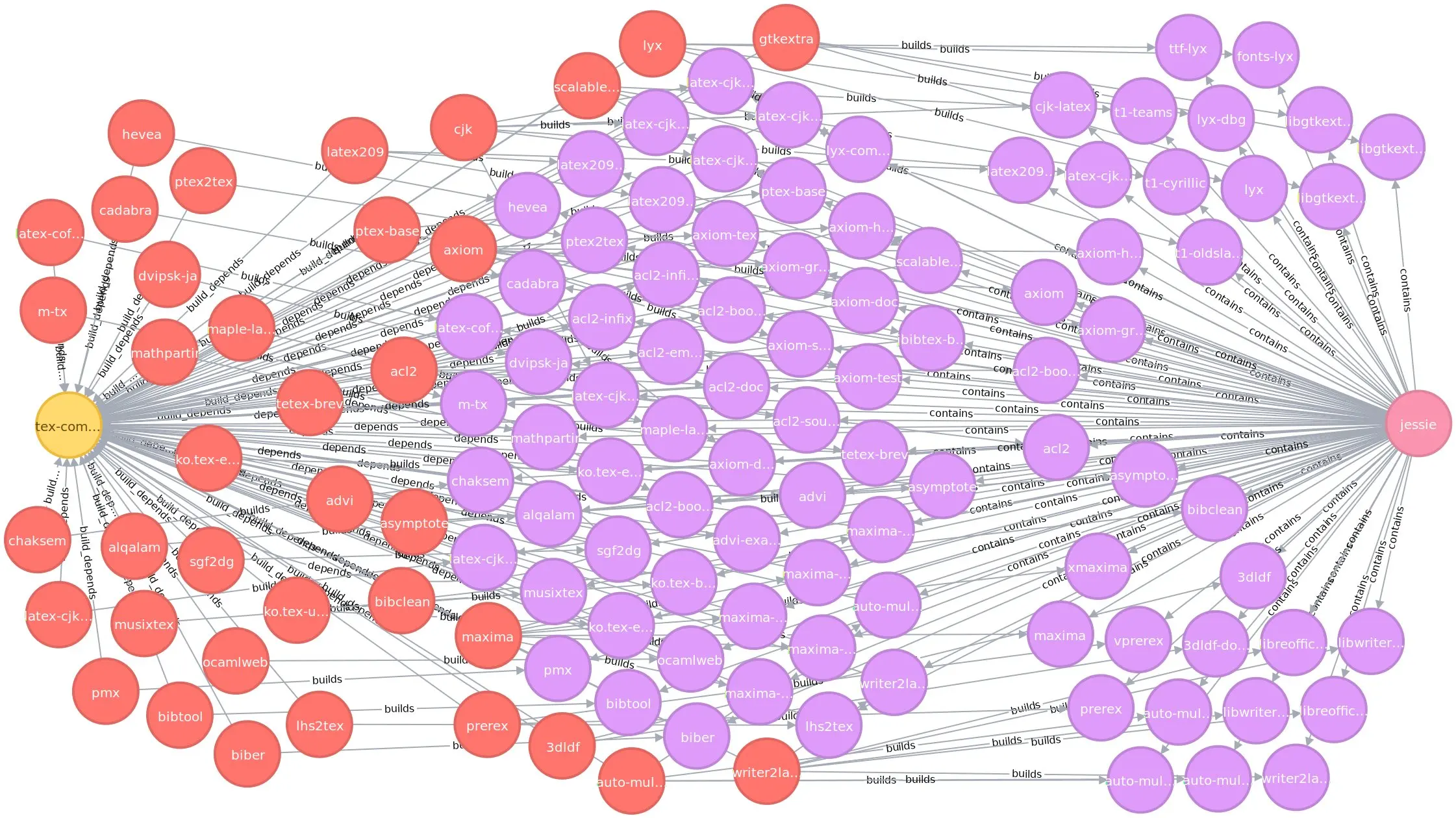
(click to enlarge)
match (S:suite)-[:contains]->(VBP:vbp)-[:builds]-(VSP:vsp)-[:build_depends]-(X:bp)
where S.name = "sid"
with X.name as pkg,count(VSP) as cntr
return pkg,cntr order by -cntr
which returns the top package debhelper with 55438 packages build-depending on it, followed by dh-python (9289) and pkg-config (9102).
Conclusions and future work
We have shown that a considerable part of the UDD can be transformed and be represented in a graph database, which allows to efficiently and easily express complex queries about relations between the packages.
We have seen how conversion of an old and naturally grown RDB is a laborious job that requires lots of work - in particular domain knowledge is necessary to deal with subtle inconsistencies and corner cases.
Lessons we have learned are
・Finding a good representation is not a one-shot thing, but needs several iterations and lots of
domain knowledge;
・using Cypher is only reasonable for query but not for importing huge amounts of data
・visualization in Chrome or Firefox is very dependent on the version of the browser,
the OS, and probably the current moon phase.
There are also many things one could (I might?) do in the future:
Bug database: Including all the bugs reported including the versions in which they have been fixed would greatly improve the usefulness of the database.
Intermediate releases: Including intermediate releases of package that never made it into a release of Debian by parsing the UDD table for uploads would give a better view onto the history of package evolution.
Dependency management: Currently we carry the version and relation type as attribute of the dependency and pointing to the unversioned package. Since we already have a tree of versioned packages, we could point into this tree and only carry the relation type.
UDD dashboard: As a real-world challenge one could rewrite the UDD dashboard web interface using the graph database and compare the queries necessary to gather the data from the UDD and the graph database.
Graph theoretic issues: Find dependency cycles, connected components, etc.
This concludes the series of blog entries on representing Debian packages in a graph database.
■関連ページ
【アクセリアのサービス一覧】
・サービスNAVI
We have seen how conversion of an old and naturally grown RDB is a laborious job that requires lots of work - in particular domain knowledge is necessary to deal with subtle inconsistencies and corner cases.
Lessons we have learned are
・Finding a good representation is not a one-shot thing, but needs several iterations and lots of
domain knowledge;
・using Cypher is only reasonable for query but not for importing huge amounts of data
・visualization in Chrome or Firefox is very dependent on the version of the browser,
the OS, and probably the current moon phase.
There are also many things one could (I might?) do in the future:
Bug database: Including all the bugs reported including the versions in which they have been fixed would greatly improve the usefulness of the database.
Intermediate releases: Including intermediate releases of package that never made it into a release of Debian by parsing the UDD table for uploads would give a better view onto the history of package evolution.
Dependency management: Currently we carry the version and relation type as attribute of the dependency and pointing to the unversioned package. Since we already have a tree of versioned packages, we could point into this tree and only carry the relation type.
UDD dashboard: As a real-world challenge one could rewrite the UDD dashboard web interface using the graph database and compare the queries necessary to gather the data from the UDD and the graph database.
Graph theoretic issues: Find dependency cycles, connected components, etc.
This concludes the series of blog entries on representing Debian packages in a graph database.
■関連ページ
【アクセリアのサービス一覧】
・サービスNAVI
Norbert Preining
アクセリア株式会社 研究開発部 所属
北陸先端科学技術大学院大学ソフトウェア検証研究センター 研究員
ウィーン工科大学 研究員
Debian開発者
TeX User Group (取締役会員)、Kurt Gödel Society (取締役会員)
ACM, ACM SigLog, 日本数式処理学会、ドイツ数学論理学会
北陸先端科学技術大学院大学ソフトウェア検証研究センター 研究員
ウィーン工科大学 研究員
Debian開発者
TeX User Group (取締役会員)、Kurt Gödel Society (取締役会員)
ACM, ACM SigLog, 日本数式処理学会、ドイツ数学論理学会










Contact usお問い合わせ
サービスにご興味をお持ちの方は
お気軽にお問い合わせください。
Webからお問い合わせ
お問い合わせお電話からお問い合わせ
03-5211-7750
平日09:30 〜 18:00