時系列データから異常を検出するための方法

時系列データから異常を検出する
今回は、複数の時系列データから異常を予測したり検出するための方法を紹介します。
複数の時系列データをもつものは、いたるところにあります。例えば、
このようなデータの中から、異常を見つけることは非常に重要で、機械学習と統計のコアテクノロジーの一つとなっています。時系列の季節変化に対処するための手法(ARIMAモデルなど)を含め、多くの手法が開発されています。
例として下記の図を見ましょう。
これは、あるインターネット接続データのARIMAモデルを作成したものです。
実際のデータ(青)、予測(黒)、3σ帯(赤、緑)と異常検知(黄)。
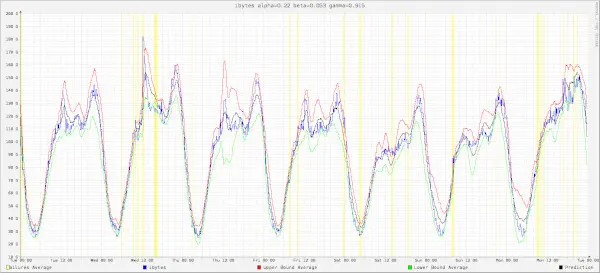
しかし、異常検知(黃)の回数が多く、実際には使えないデータとなりました。
複数の時系列データをもつものは、いたるところにあります。例えば、
- スマートウェアラブルを使用したときに取得される、1日あたりの歩数や1分あたりの心拍数。
- 工場で計測できる、温度、ノイズ、振動などの種類の測定値。
- ネットワーク環境では、パケット数やバイト数、1秒あたりの接続数。
このようなデータの中から、異常を見つけることは非常に重要で、機械学習と統計のコアテクノロジーの一つとなっています。時系列の季節変化に対処するための手法(ARIMAモデルなど)を含め、多くの手法が開発されています。
例として下記の図を見ましょう。
これは、あるインターネット接続データのARIMAモデルを作成したものです。
実際のデータ(青)、予測(黒)、3σ帯(赤、緑)と異常検知(黄)。
しかし、異常検知(黃)の回数が多く、実際には使えないデータとなりました。
時系列を同時に処理する場合に有効な方法
このように、多くの異なる時系列を同時に処理する場合に有効な方法を紹介したいと思います。例として、工場の機械のセンサーを挙げます。
簡単なアプローチの1つは、利用可能なデータ(またはデータウィンドウ)からの各センサーの平均と標準偏差の推定量を計算し、平均から離れている標準偏差の倍数であるz値を計算して新しい測定値とします。正規分布では、測定値の99.7%以上が平均値の周りの3σ帯内にあって、z値は3より小さい値です。各センサーを個別に確認し、新しい測定値に対してこの計算が実行され、測定値の1つが3σ帯(または2σ帯)領域の外側にある場合、アラームが発生します。
残念ながら、センサーの数が多いと、異常な動作を報告するセンサーが常にいくつかある状態となり、非常に高い偽陽性率、または多くの異常の見逃しが発生します。この問題に対処するために、eBayのエンジニアは、関連する時系列の大規模なグループの異常を予測するための興味深い方法[1]を開発しました。
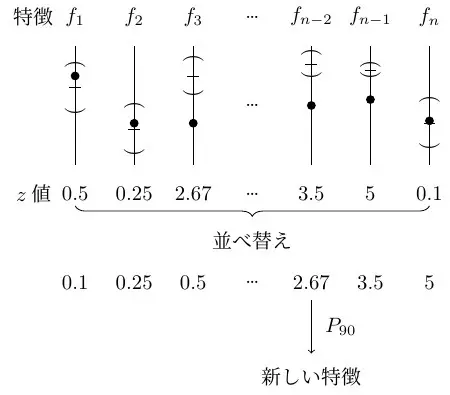
彼らが採用した方法では、すべての特徴の「サプライズ」値(z値のような値)をサイズによって並べて、そこの中の90パーセンタイルを新しい特徴として使いました。これですべての時系列から新しい特徴を設計して、特徴の変更とその分布を数値化する新しい時系列データが得られます。最後に、通常の3σルールを使用して、この新しい特徴の平均とz値を異常の指標として使用します。
論文[1]でこの方法がeBayで、ある履歴データで非常にうまく認識し、高いFスコアで異常を確実に認識できると報告しました。
アクセリアでは、約3,000の特徴のセットを使用して、接続メタデータに同じ方法で実験しました。この方法で、データに見られる異常が正しく予測されたことを確認できました。「サプライズ」値の変わりに、曜日と時間帯に分けてz値を使用しました。
[1] D. Goldberg, Y. Shan. The Importance of Features for Statistical Anomaly Detection. In 7th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 15), USENIX Association,2015.
https://tech.ebayinc.com/engineering/statistical-anomaly-detection/
■関連ページ
【アクセリアのサービス一覧】
・サービスNAVI
簡単なアプローチの1つは、利用可能なデータ(またはデータウィンドウ)からの各センサーの平均と標準偏差の推定量を計算し、平均から離れている標準偏差の倍数であるz値を計算して新しい測定値とします。正規分布では、測定値の99.7%以上が平均値の周りの3σ帯内にあって、z値は3より小さい値です。各センサーを個別に確認し、新しい測定値に対してこの計算が実行され、測定値の1つが3σ帯(または2σ帯)領域の外側にある場合、アラームが発生します。
残念ながら、センサーの数が多いと、異常な動作を報告するセンサーが常にいくつかある状態となり、非常に高い偽陽性率、または多くの異常の見逃しが発生します。この問題に対処するために、eBayのエンジニアは、関連する時系列の大規模なグループの異常を予測するための興味深い方法[1]を開発しました。
彼らが採用した方法では、すべての特徴の「サプライズ」値(z値のような値)をサイズによって並べて、そこの中の90パーセンタイルを新しい特徴として使いました。これですべての時系列から新しい特徴を設計して、特徴の変更とその分布を数値化する新しい時系列データが得られます。最後に、通常の3σルールを使用して、この新しい特徴の平均とz値を異常の指標として使用します。
論文[1]でこの方法がeBayで、ある履歴データで非常にうまく認識し、高いFスコアで異常を確実に認識できると報告しました。
アクセリアでは、約3,000の特徴のセットを使用して、接続メタデータに同じ方法で実験しました。この方法で、データに見られる異常が正しく予測されたことを確認できました。「サプライズ」値の変わりに、曜日と時間帯に分けてz値を使用しました。
[1] D. Goldberg, Y. Shan. The Importance of Features for Statistical Anomaly Detection. In 7th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 15), USENIX Association,2015.
https://tech.ebayinc.com/engineering/statistical-anomaly-detection/
■関連ページ
【アクセリアのサービス一覧】
・サービスNAVI
Norbert Preining
アクセリア株式会社 研究開発アドバイザー
北陸先端科学技術大学院大学ソフトウェア検証研究センター 研究員
ウィーン工科大学 研究員
デビアン開発者
TeX User Group (取締役会員)、Kurt Godel Society (取締役会員)
ACM, ACM SigLog, 日本数式処理学会、ドイツ数学論理学会
北陸先端科学技術大学院大学ソフトウェア検証研究センター 研究員
ウィーン工科大学 研究員
デビアン開発者
TeX User Group (取締役会員)、Kurt Godel Society (取締役会員)
ACM, ACM SigLog, 日本数式処理学会、ドイツ数学論理学会










Contact usお問い合わせ
サービスにご興味をお持ちの方は
お気軽にお問い合わせください。
Webからお問い合わせ
お問い合わせお電話からお問い合わせ
03-5211-7750
平日09:30 〜 18:00